
There are a lot of good research projects going on in Europe: if you didn’t hear about them, it is simply because they are not receiving the media attention they deserve. One of such projects is the Fraunhofer parallel file system, which is being developed by the Institute for Industrial Mathematics, part of the Fraunhofer Society, since 2005.
There have been several major installations of FhGFS during the last years (and more are coming), but this year, 2013, appears to be a definitive point for the project, characterised by a substantial increase in download counts. Latest presentation at SC13 in the USA also attracted attention (you can fetch the slides at the project’s website, FhGFS.com).

Users of FhGFS. Source: presentation made at SC13.
To learn what makes FhGFS so special, I decided to contact Sven Breuner, team lead for the FhGFS project. The conversation quickly became “an interview by e-mail”, which I present to you below.
K.S.: I just read that FhGFS was selected for the DEEP-ER project — my congratulations!
Thanks! Fraunhofer as a research organization is of course always glad to participate in research projects and similar collaborations world-wide. But the fact that FhGFS is the only cluster file system of European origin and some of its special properties like the distributed metadata architecture make it especially well-suited for this kind of projects.
K.S.: Does this mean that FhGFS is only developed for research purposes and not for production?
No, FhGFS is primarily developed for production use. Research projects is only one way of how development of new features is funded. But the FhGFS version that is available for download from www.fhgfs.com is completely stable and mature.
In fact, FhGFS is already in production use since 2009 now, but it took a few years to gain some trust, because based on the problems that people had with previous generations of cluster file systems, there was a wide-spread belief that it’s somehow in the nature of cluster file systems to be unstable and hard to maintain.
Based on the download count that we’re seeing since last year and the feedback that we get, I think we finally convinced the people that this is really not the case with FhGFS.
K.S.: How does FhGFS compare to parallel NFS (pNFS) in its features?
The problem with pNFS is that it is still NFS, thus the fundamental idea is still not to provide a file system for scientific / cluster use.
So if you run cluster jobs with pNFS, you will still have cases where one node creates a file and sends a message to the other node “I created file xy, you can read it now” and the other node gets a “file not found”, because the (p)NFS client is relying on outdated cached information.
Another problem with (p)NFS is that it can silently corrupt file contents when multiple processes from different nodes are writing to non-overlapping regions of a shared file, which is caused by the 4KB granularity of the page cache that (p)NFS uses.
…These are problems that you won’t have with FhGFS.
Of course that doesn’t mean that (p)NFS is a bad thing – the aggresive caching also has its advantages, but (p)NFS in general is rather useful as a “home” file system or so, not for the typical scientific workloads.
K.S.: I thought NFS enforces cache coherence through the use of file locks!
The mandatory locks are only enforced in the moment when a client actually reads from or writes to a storage server/device. They do not enforce cache coherence.
I also wasn’t sure about this when I first heard about NFSv4(.1) and pNFS a few years ago, so I asked Mike Eisler (he is one of the authors of RFC5661) at that time, especially because I read an article at that time about pNFS, which stated that pNFS would provide cache coherence. He replied that pNFS cannot enforce cache coherence (it’s also clearly stated in RFC5561 section 10: “The NFSv4.1 protocol does not provide distributed cache coherence”), so the problem that I’m talking about still exists with NFS4.1.
K.S.: Did you ever experience this silent data corruption?
I didn’t experience the silent data corruption myself (because I’m not writing scientific applications), but every now and then I have colleagues coming to me asking why their distributed compute job produces corrupt output when they run it in their home directory (i.e. NFS mount), but produces sane output when running on an FhGFS.
To explain the problem, I have attached two images. Basically it just means that you cannot update an arbitrary byte range, but instead you at least have to read one entire block/page (i.e. 4KB in case of the Linux page cache) first, then update the page, then write out the complete updated page.
So this is what Example 1 shows: Assume you have a 1GB sized file and your application wants to update only a single byte at offset 2 (i.e. only the second byte) in that file. In this case, the NFS client will transparently read the entire 4KB page, then updates the single byte at the given offset within this 4KB page and will then anytime later send the updated 4KB page to the server:
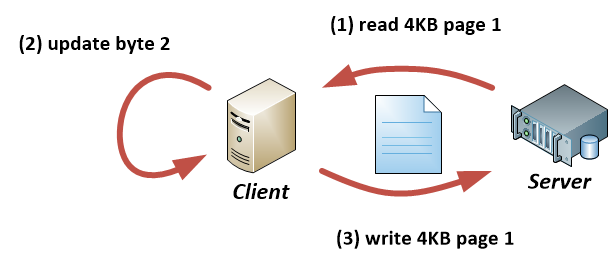
Example 1: “Read-modify-write” scenario.
It’s important to note here that as long as you don’t call fsync() or explicitly close() the file, you don’t know when the client will send the updated page to the server (=> normal write-back caching).
Example 2 shows how this leads to data corruption through lost updates, when two different clients are writing to a shared file: from the application point of view, each client is updating a different region of the file (e.g. writing its computation result to its own dedicated byte-range in the file). But as the NFS client works with full 4KB pages, one of the updates from the clients will be lost, because both clients try to update data on the same page:
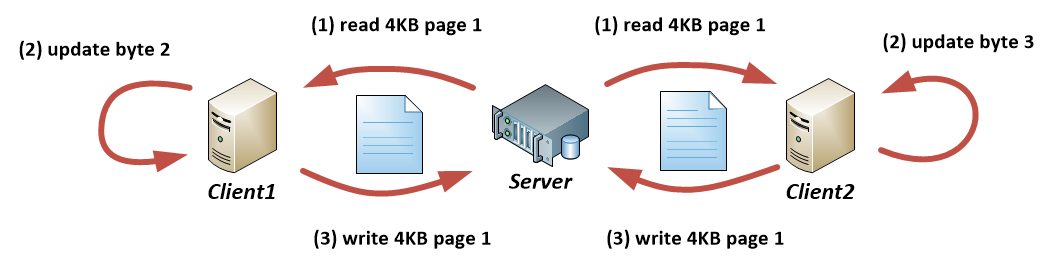
Example 2. Two clients try to update their regions, which are non-overlapping but still belong to the same “page” in each client’s memory. The client that writes last wins.
The only way to avoid this corruption would be to completely serialize updates to the file and not keep the file open on one client while another client is updating it. But that’s far away from the idea of parallel IO, of course!
K.S.: Do you have any plans to make a video with a demonstration of how quickly one can set up a file system with a couple of servers and one or two clients?
Haven’t thought about that yet, but definitely sounds like a good idea.
K.S.: Are there any plans for MS Windows clients for FhGFS? People often want to work with computation results from their personal computers, and having native access from MS Windows will help a lot. Or maybe enough documentation is planned to be published so that third parties can create clients?
We hear that question quite often and I would really like to see a native Windows client. The problem here is that we need to ensure that it will somehow earn us the money that we invest in the development of such a client. And that doesn’t seem to be the case yet, given our current focus on HPC, which is mostly a Linux world.
But that topic keeps coming back up every few months in the team meetings, so I think one day we will have a native Windows client, but not in the next few months.
On the other hand, it’s always an option to re-export a FhGFS client mount via Samba — of course, with reduced performance compared to a native client, but often still good enough for most people to work with their result files.
And the FhGFS client (including the FhGFS network protocol) is already under GPL, so anyone could start right away to try to wrap up the existing code in a “Windows-style” file system driver.
K.S.: I heard that FhGFS is lock-free — is that true and how does it work? If we don’t use locks, don’t we need some other synchronisation mechanism?
That’s right. Other cluster file systems typically use the Linux page cache or a similar block-based cache approach and thus require special distributed locking to avoid the problems that NFS has with shared file access. They have to lock pages that are currently modified/cached by one of the clients and other clients have to recall the lock from that client if they want to modify the same page.
The problem is that this distributed locking has a severe impact on N:1 write performance (i.e., multiple clients writing to the same shared file), because it leads to a serialization of access and extra network traffic for lock management.
For FhGFS, we implemented a cache protocol that is not based on fixed block sizes and thus can handle arbitrary byte ranges. So when an application on a certain client updates the 2nd byte in a file, we can really send only this single byte to the server. This eliminates the need for distributed locks in the context of shared file writes.
K.S.: Now does it mean that you still use locking, but it is very fine-grained, applicable to arbitrary byte ranges? For those familiar with the Linux kernel internal workings, it will be interesting to know what happens “under the hood” — in the kernel and in the FhGFS loadable kernel module — when the user application requests to modify just the 2nd byte in a file?
The locking can be handled locally within the client and the server (e.g. the server locally takes care of consistency of internal data structures and the underlying FS when multiple processes are writing to the same file), that’s the important thing to gain scalability, similar to any other distributed application.
The Linux kernel in general provides frameworks for several file system related things like the page cache, the directory entry cache and such, but it also allows you to go your own ways, if you want to, which is what we did in the case of read() and write().
K.S.: With the size of storage arrays continuously growing, what features of FhGFS will save us from “bit rot” and other types of unrecoverable errors — is using ZFS as an underlying file system for FhGFS a reliable solution?
We see bit rot protection as a job for the underlying file system or the block device layer, because sitting on top of a local Linux FS, FhGFS could save/verify checksums for its chunkfile contents, but it cannot checksum or protect the metadata of the underlying local FS. That’s why this has to be taken care of at a lower level.
On a block device level, people already have checksums by using RAID-6 nowadays, and Linux software RAID or a modern hardware RAID controller can run consistency checks to detect and fix bit rot. There is also some work going on currently for XFS and ext4 regarding checksums to protect from bit rot.
Using ZFS together with FhGFS is clearly also an option and I really like the idea of combining the RAID and the file system layer for its performance advantages. For ZFS, it actually even seems like the FhGFS user community is already one step ahead of us: while we have just tested basic functionality of FhGFS on top of ZFS, users are already exchanging knowledge about important tunings and report FhGFS+ZFS production usage on the fhgfs-user mailing list. We are a bit more focussed on Btrfs at the moment, where we are also doing performance analysis and submitting patches.
K.S.: What about opening the source code for the server part? This would create more trust, because people want to know what happens to their data (even if they will never read the source code). And should any bugs need to be fixed or features added, your clients would find it easiest to hire you, because as the professionals who wrote the code you have the highest chances to complete the work in reasonable time frame and within budget.
The FhGFS server components will be open-sourced. It was publicly announced in June at the International Supercomputing Conference 2013 (ISC’13), and it is even guaranteed as part of the DEEP-ER project. However, while I’m also looking forward to this, I cannot say a date for it yet, so in the worst case it might not even happen in the next months, but it will definitely happen sooner or later.
In the meantime, we are doing NDAs with some supported customers that have the need to modify certain parts of FhGFS on a per-project basis, and we have the option to provide the complete source code to larger customers, for whom access to the source code might be business critical.
(End of interview)
So now that it turns out that Parallel NFS (pNFS), on which I pinned some hopes, doesn’t support distributed cache coherency, FhGFS could very well be a suitable replacement.
Fraunhofer Society already decided to open the source code for the client application (see the question “Is FhGFS open-source?” in the FhGFS FAQ), and the server part will be open-sourced sometime in the future. We already have another parallel file system which is open-source, enterprise-grade and has commercial support: Lustre. What FhGFS promises to add to this mix is the ease of installation and maintenance. Let’s see how the plan works out!
Many thanks to Sven for answering the questions, and let’s wish luck to the German team that wants to conquer the world with their parallel file system. If you want to download and try it out, go to the project’s website. Additionally, some nice benchmarking results for FhGFS (in comparison with GlusterFS) were made available in June 2013 by Harry Mangalam, Ph.D. of University of California, Irvine.